
reinforcement-learning
강화학습
-
쉽지만 추상적인 버전
시행 착오를 통해 발전해 나가는 과정
-
어렵지만 좀 더 정확한 버전
순차적 의사결정 문제에서 누적 보상을 최대화 하기 위해 시행착오를 통해 행동을 교정하는 학습 과정
강화 학습이 풀고자 하는 문제는 바로 순차적 의사결정 문제이다
보상
보상이란 의사결정을 얼마나 잘하고 있는지 알려주는 신호입니다.
강화학습의 목적은 과정에서 받는 보상의 총합, 즉 누적 보상을 최대화 하는 것이다.
보상의 3가지 특징
- 어떻게 X 얼마나 O
- 보상은 행동에 대한 평가를 해줄 뿐,어떻게 해야 높은 보상을 얻을 수 있을지 알려주지 않는다.
- 보상이 어떻게 해야할지는 알려주지 않지만 보상이 낮았던 행동들은 덜 하고 , 보상이 높았던 행동들은 더하면서 보상을 최대화하도록 행동을 조금씩 수정해나간다.
- 스칼라
- 스칼라는 벡터와 다르게 크기를 나타내는 값 하나로 이루어져 있다.
-
목표가 여러개라면 하나의 스칼라 형태로 표현해줘야한다.
각 목표에 가중치를 둬서 하나의 숫자로 합쳐야 한다.
- 강화학습은 스칼라 형태의 보상이 있는 경우에만 적용할 수 있다.
- 희소하고 지연된 보상
- 행동과 보상이 일대일로 대응하지않고 선택했던 행동의 빈도에 비해 훨씬 가끔주어지거나 한참 뒤에 나올 수 도 있다.
- 밸류 네트워크등의 다양한 아이디어가 등장하였다.
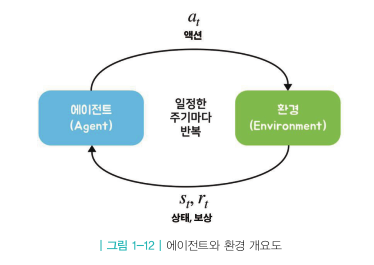
에이전트
에이전트가 액션을 하고 그에 따라 상황이 변하는 것을 하나의 루프라 했을 때 루프가 끊임없이 반복되는 것을 순차적 의사결정이라고 한다.
에이전트는 강화학습의 주인공이자 주체이다.
- 현재 상황 $S_t$ 에서 어떤 액션을 해야 할지 $a_t$를 결정
- 결정된 행동 $a_t$를 환경으로 보냄
- 환경으로부터 그에 따른 보상과 다음 상태의 정보를 받음
환경
에이전트를 제외한 모든 요소
현재 상태에 대한 모든 정보를 숫자로 표현하여 기록해 놓으면 그것을 상태라고 한다,
환경은 결국 상태 변화를 일으키는 역할을 담당하고 있다.
- 에이전트로부터 받은 액션 $a_t$를 통해서 상태 변화를 일으킴
- 그 결과 상태는 $S_t \rightarrow S_{t+1}$로 바뀜
- 에이전트에게 줄 보상 $r_{t+1}$도 함께 계산
- $S_{t+1}$과 $r_{t+1}$을 에이전트에게 전달
순차적 의사결정 문제에서는 시간의 흐름을 이산적으로 생각한다.
이러한 시간 단위를 틱 혹은 타임 스텝이라고 한다
Leave a comment